This blog post is the third and last of a series of posts that aims at bringing some light into the terminological thicket of privacy engineering. The series primarily aims at illustrating the goals and functions of privacy engineering and how they can be implemented through different technologies. To inform this discussion, it will (if only briefly) also touch on the theoretical underpinnings of privacy and privacy engineering.
Tl;dr: The earlier parts of this series discussed abstract privacy and privacy engineering concepts. This part looks at technological building blocks that can be used to build privacy-friendly systems. In particular, it provides a high-level overview of privacy-preserving technologies that are available for integration in systems today.
In contrast to the first two parts, I did not write this post alone. Instead, fellow privacy enthusiast Shalabh Jain and I teamed up to jointly write this final part of the series.
The first part of this series provided an overview on different definitions of privacy engineering. Part 2 discussed the goals of privacy engineering, different notions of privacy and how privacy definitions and data protection obligations can be translated into privacy engineering protection goals.
But what to do with all this rather abstract information when you actually want to build a product or service? We try to elaborate upon some available tools here. To not create false expectations: this post can certainly not provide a thorough overview on how to build a privacy-preserving system. What it will provide, however, is a glimpse into the fascinating world of privacy technology. In particular, it will discuss so-called “privacy-preserving technologies” (PPTs).
Note: for brevity, we will use “system” to refer to both products and services. Additionally, for this post, we implicitly subsume data protection under the umbrella term “privacy” for brevity and do not distinguish between the two concepts unless necessary.
Building privacy-preserving systems
Before going into the “how” of building privacy-preserving systems, let’s quickly remind ourselves of the “why”. Why should one go to the lengths of building privacy-preserving systems? The last part of this series illustrated that privacy engineering aims at two goals. One goal is, of course, compliance with data protection legislation and risk reduction. However, building a system that is compliant with data protection legislation should, while certainly necessary, not be the sole purpose of privacy engineering activities. Actually, this would be a little like getting a gym membership but only going to the gym once a month so as to get a health insurance discount. Sure, you’ll get your discount, but you will still miss out on most of the benefits of your membership.
As discussed in the last post, the full potential of privacy engineering will only be unleashed when it is aimed at building trustworthy systems just as much, if not more, as at building systems that are “just” compliant. That being said, let’s have a look into how to build privacy-preserving and trustworthy systems.
Part 2 illustrated that building privacy-preserving systems means, among others (!), to build them such that at least the relevant protection goals are fulfilled. Fulfilling these goals requires appropriate development processes on the one hand and the right technological building blocks, on the other hand. As described in the last post, the privacy-by-design paradigm (and the DPbDD obligation of Art. 25 GDPR, see also Part 2) requires that privacy aspects be considered during the complete development cycle. To again cite the ICO, “[one has] to integrate or ‘bake in’ data protection into [one’s] processing activities and business practices, from the design stage right through the lifecycle”.
Baking in privacy will obviously mean different things at different points of the development lifecycle. For example, in the early steps of the development cycle it might relate to fundamental considerations regarding data collection strategies and the overall system concept. These might, e.g., concern decisions regarding what data to collect in the first place or the decision between local processing on user devices and centralized processing of data. In later steps you might want to use specific privacy design patterns to bake in privacy or implement specific technical measures*.
Consequently, privacy engineering comprises activities as varied as privacy or data protection impact assessments, selection of technical and organizational measures, implementation of these measures, documentation, more documentation, and then some. Once the system is in operation, data needs to be classified and inventoried, data subject requests need to be answered, the system and its environment including the threat landscape need to be monitored etc. Obviously, a blog post is far from sufficient to touch on all those points even superficially. Hence, we will focus on technical measures in general and privacy-preserving technologies in particular.
*Sidenote: Some privacy-preserving technologies you might choose to implement might also “implicitly define a corresponding privacy design pattern” (J.-H. Hoepman). We will not discuss privacy design strategies and patterns here, as there is plenty of literature on the topic, e.g., by Colesky et al., Romanosky et al. and many others.
Privacy-Preserving Technologies
So, what exactly are privacy-preserving (and privacy-enhancing) technologies? In a nutshell, privacy-preserving technologies (PPTs) are building blocks that aim at fulfilling privacy or data protection engineering goals such as the protection goals described in Part 2.
Alas, there is quite a variety of different definitions and taxonomies of PPTs and the discussions over terminology and fundamental definitions described in this series’ first two parts do not stop at PPTs. If you are less interested in these discussions, you might want to skip the next paragraph.
One can easily dive into long discussions on whether to use the term “privacy-enhancing technologies” (PETs) or rather speak of “privacy-preserving technologies” (PPTs). We will refrain from a deep-dive into this discussion but to give you a brief overview: some criticize the term “privacy-enhancing technologies” on two levels. On a more philosophical level, the term PET is criticized for implying that it would be within a data controller’s discretion whether to enhance (or not) the level of privacy that a given system provides compared to a previously lower level. This, in turn, would imply that privacy is something that could be “granted” to a data subject rather than something that he or she is entitled to in the first place. This would be particularly problematic as the term PETs is understood by some as primarily referring to user-deployed technologies, such as cookie blockers. It is, however, not a data subject’s responsibility to employ (often hard to use) technology to preserve his or her privacy in an act of “digital self-defense”. On an engineering-focused level, critics of the term privacy-enhancing technologies argue that the term would imply that privacy-friendliness could be achieved by adding a PET to an otherwise privacy-invasive system to enhance privacy. This would of course, so the argument, be in stark contrast to the privacy-by-design approach and would seldomly lead to a privacy-friendly and compliant system.
That being said, let’s have a closer look at what PPTs are and which types of them exist. For simplicity’s sake and to be able to use existing terminology, we will use the following rough taxonomy:
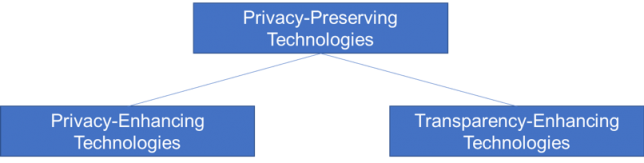
In this coarse-grained taxonomy, privacy-preserving technologies encompass the sub-classes “privacy-enhancing technologies” and “transparency-enhancing technologies”. The former aim primarily at the protection goals of data minimization, confidentiality, and unlinkability. In contrast, the latter’s focus lies on transparency and intervenability.
There are, of course, many other ways to categorize PETs, PPTs and TETs. For example, PETs can also be sub-divided into soft and hard PETs. Moreover, TETs are sometimes considered a subclass of PETs instead of a class of its own rights on the same level as PETs. Further, some do not distinguish between privacy-preserving and privacy-enhancing technologies at all. Finally, our categories and sub-categories could also be sub-divided further and are not always completely disjoint. However, this rough taxonomy will suffice for a general discussion. You can find other, partly more fine-grained, taxonomies in the articles linked at the end of this post.
Privacy-Enhancing Technologies
Based on the definition by Heurix et al., Privacy-Enhancing Technologies belong to a class of technical measures which aim at preserving the privacy of individuals or groups of individuals. The primary focus of PETs lies in data minimization, which is achieved mainly through the protection goals of “confidentiality” and “unlinkability”. Some of them also achieve the goals of “indistinguishability”, “unobservability” or “deniability”, which are not part of the protection goals considered in the SDM but can be considered aspects of data minimization (see Pfitzmann & Hansen).
Intuitively, any technical measure for ensuring the confidentiality personal data, or removing linkage to personal data can be classified a PET for a certain class of systems. Some examples of PETs that are common in everyday use are, email encryption, the Signal protocol, Tor routing, and attribute-based credentials (e.g., Idemix, IRMA). While these are good examples of tools that find more applications in building trustworthy systems rather than compliant systems, they are application specific. Traditionally, the term PET is used in context of technologies that enable privacy for more general-purpose computation.
Broadly speaking, PETs in this context achieve the privacy goals by three distinct mechanisms, namely,
- Isolating the computation/processing by using specialized hardware or cryptographic primitives that provide such guarantees, e.g., trusted execution environments, secure multi-party computation or homomorphic encryption.
- Performing computation/processing to modify the data itself to reduce leakage of information, e.g., differential privacy or k-anonymity.
- Performing computation/processing on inputs that are statistically similar to or derived from the true inputs, yet do not leak information about the true values of the input data, e.g., synthetic data generation or federated learning.
We will discuss a few of the commonly used PETs in the following.
Differential Privacy – Mechanisms for achieving so-called differential privacy are great examples of PETs. Differential privacy itself is not a technology but a definition of privacy, namely a “robust, meaningful, and mathematically rigorous definition” (Dwork & Roth, 2014). We will skip over the math here and go straight to the essence of the definition: differential privacy ensures that the absence or presence of a particular individual’s data in a data set does not meaningfully change the result of an analysis of the data set. In other words, “differential privacy promises to protect individuals from any additional harm that they might face due to their data being in the private database x that they would not have faced had their data not been part of x” (Dwork & Roth, 2014). Differential privacy can be achieved by adding carefully tailored random noise to analysis results. It is widely used to prevent the leakage of personal data from aggregated statistics, e.g., by the US Census Bureau, by Apple for emoji suggestions or by Microsoft for telemetry analysis.
Trusted execution environments (TEEs) – TEEs aim at confidentiality of code and data where some also provide integrity protection. There are several approaches to TEEs, with process-based and VM-based TEEs being the most common. We will not discuss those in detail but will stick to a general overview. If you want to gain more in-depth insights on the different types of TEEs, you might find this nice overview by Redhat helpful. Generally speaking, TEEs rely on main processor features to ensure confidentiality and integrity. Usually, this means that immutable private keys burnt into processors during manufacturing are used as hardware root of trust. Examples of TEEs include Intel SGX, ARM TrustZone or AMD SEV. Trusted execution environments are used to allow trustworthy computation in untrusted environments using memory encryption where only calls from within the secure environment can lead to on-the-fly decryption within the processor. That way, code and data within the TEE are secured even against the host system. In this presentation at Microsoft Build, our colleague Stefan Gehrer illustrates how TEEs could be used to increase security of personal data in machine learning.
Homomorphic Encryption – In contrast to TEEs, software-based PPCTs such as homomorphic encryption (HE) or secure multiparty computation (MPC) do not rely on hardware-based roots of trust but on the hardness of the mathematical problems they build upon. Homomorphic encryption “allows computation to be performed directly on encrypted data without requiring access to a secret key” (Homomorphic Encryption Standardization Consortium). While HE is still far too computationally expensive for many use cases, it is actively being used, for example, in Microsoft’s Edge browser for checking for breached passwords.
Secure multiparty computation (MPC) – MPC aims at “[enabling] a group of independent data owners who do not trust each other or any common third party to jointly compute a function that depends on all of their private inputs” (Evans et al.). A very common use case for MPC is so-called private set intersection (PSI) where several parties, each holding a set of data items, want to learn the intersection of their sets without disclosing any elements outside the set intersection. We will not go further into detail here but refer the reader to the literature linked at the end of this post for more information. The “pragmatic introduction to MPC” by Evans et al. is a great starting point to familiarize yourself with the topic. If you want to get more hands-on, you could check out the cloud native MPC stack Carbyne Stack (website, github) developed in the Bosch Research project SPECS.
Transparency-Enhancing Technologies
As the name suggests, TETs aim at the privacy protection goals “transparency” and, to some extent, “intervenability”. They can be defined as “tools which can provide to the individual concerned clear visibility of aspects relevant to [its personal] data and the individual’s privacy”. Hence, TETs primarily aim at providing data subjects with information about a data controller’s claimed and actual processing activities. So-called privacy dashboards are probably the most prominent type of TETs. A privacy dashboard constitutes a central access point to privacy-relevant information relating to the user. Using it, data subjects can gain insight into the data relating to them held by a data controller and its usage. The figure below exemplarily depicts an iPhone’s “app privacy report”, which can be considered a privacy dashboard.
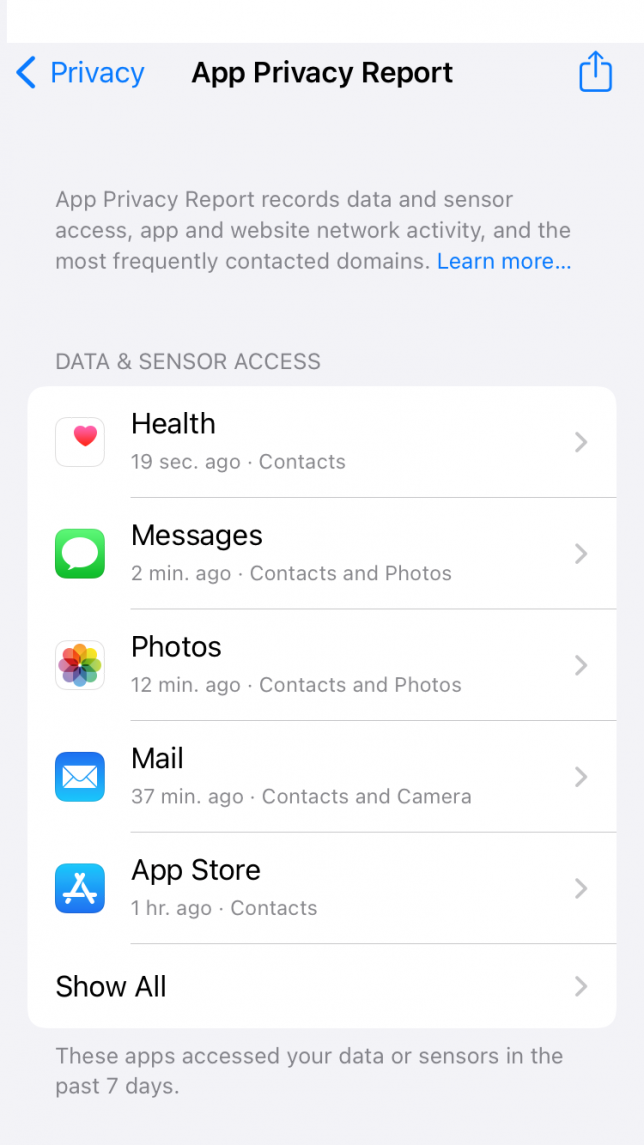
Some TETs additionally provide users with functionality for exercising some level of control over the collected data and its usage. For example, a privacy dashboard can also provide users with functionality to rectify collected data or issue other data subject requests. The depth and width of the insight and control provided by a TET depends on the specific type of TET and the provider’s goals. If you are interested in a more in-depth discussion of TETs, this relatively recent survey by Murmann & Fischer-Hübner will be a good starting point.
If one wants to take a very broad definition of TETs, some privacy technology aimed at data controllers can also be considered TETs or comprising transparency-enhancing components. These could include, e.g., tools for providing information regarding where personal data is stored, which data relates to which user and more. Transparency-enhancing components in tools like these will help controllers in fulfilling legal requirements regarding transparency, documentation and accountability. Examples include data discovery functionality in data protection management tools. You can find a huge selection of available privacy technologies including such that could be considered transparency-enhancing, e.g., in the IAPP’s Privacy Tech Vendor Report).
The Potential of PPTs and Privacy Engineering
An introductory blog post is hardly adequate to give in-depth insight into the fascinating field of privacy-preserving technology. We hope, however, that we could spark your interest in PPTs. They are, of course, no panacea and can only be one of multiple building blocks of privacy-friendly systems. Nonetheless, the field has been advancing rapidly in recent years and there is ample potential for PPTs to enable more secure and privacy-friendly data-centric business.
The above-described properties of privacy-preserving technologies have huge potential not “only” with respect to protection individuals’ data. They can also build the foundation for privacy-preserving B2B data sharing and analysis and it is easy to imagine useful applications and business cases building upon them. For example, PPTs can be used to facilitate analysis of data held by different parties without any of the parties actually having to disclose their data to the other parties. Actually, there are already real-life examples of PPT-enabled use cases, such as the Boston Women’s Workforce Council’s usage of MPC to measure the gender and racial wage gap. Other areas where PPCTs can facilitate beneficial data analysis without jeopardizing privacy are, among others, medical research (e.g. in cancer research), fraud detection and basically any use cases where different parties want to pool together their data for analysis. Interest in and development of PPTs has increased tremendously in recent years while the market for privacy tech in general is projected to also grow immensely.
However, while PPTs are gaining momentum, individuals’ privacy and autonomy are still in peril given the prevalence of business models that put surveillance revenues rather than responsible data handling front and center. In this series of posts, we tried to illustrate what privacy engineering is and how it can help create more privacy-friendly systems while at the same time supporting companies in establishing trustworthy (data-centric) business. We hope you enjoyed reading our posts.
Additional Reading
- Evans et al.: “A Pragmatic Introduction to Secure Multi-Party Computation”
- Danezis on (among others) hard privacy vs. soft privacy systems
- Heurix et al.: „A taxonomy for privacy enhancing technologies“
- Hoepman: “Privacy Design Strategies”
- Kostova et al.: “Privacy Engineering Meets Software Engineering. On the Challenges of Engineering Privacy By Design“
- Pfitzmann & Hansen: “A terminology for talking about privacy by data minimization”