This blog post is the second of a series of posts that aims at bringing some light into the terminological thicket of privacy engineering. The series primarily aims at illustrating the goals and functions of privacy engineering and how they can be implemented through different technologies. To inform this discussion, it will (if only briefly) also touch on the theoretical underpinnings of privacy and privacy engineering.
Part 1 | Part 2
Tl;dr: this part briefly discusses the “why” of privacy engineering: compliance and trust. Both aspects are linked to fundamental questions regarding what privacy actually is, as the different notions of privacy shape data protection legislation and people’s expectations. This post discusses three major “flavors” of privacy conceptualizations and illustrates protection goals for privacy engineering.
Privacy Engineering – Why bother?
The last post in this series provided different definitions of “privacy engineering”. It highlighted the prevalence of the privacy-by-design paradigm in these definitions and postulated that different theories of privacy lead to different focal points in privacy-by-design and privacy engineering.
But why is privacy engineering important in the first place? Why would one go to the lengths of establishing a privacy engineering program? Well, in general, privacy engineering serves two important goals:
Compliance: Violations of data protection regulations can easily lead to drastic fines. Proper privacy engineering practices facilitate compliance with data protection regulation, thus reducing compliance risk.
Trust: Proper privacy engineering practices facilitate the development of products/services that cater to users’ and partners’ privacy needs and preferences. This fosters customers’ and partners’ trust and can establish competitive advantages. In contrast, failure to protect privacy might lead to severe reputational damage.
Both aspects are obviously important but it is, of course, legitimate to primarily see privacy engineering as a compliance effort. However, using privacy engineering just as a means to be compliant leaves its vast potential untapped. To cite Nishant Bhajaria’s latest book, one should rather “[use] existing legal frameworks as the floor and customer trust as the ceiling […] to reach for”. That being said: there is still plenty of interesting research to do on privacy concerns, trust and their relation to actual behavior. However, it becomes increasingly clear, that good privacy practices have a positive impact on trust and business benefits. You can find a couple of links to a small selection of recent popular studies on the topic at the end of this post. This is of course only a small subset and there is also a large body of fascinating, scientific literature on the subject. If you want to learn more, you will find Acquisti’s work to be a great starting point.
What does “privacy” mean?
The two objectives described above (compliance and trust) are not only closely connected with each other but also to the question of what privacy actually is and how to achieve privacy-by-design. On the one hand, data protection laws do not appear out of thin air but build (among others) upon pre-existing values, norms and conventions regarding the usage of information about individuals. Consequently, notions of privacy resound in data protection regulations and their interpretation by courts and, hence, are indirectly linked to compliance risk.
On the other hand, common notions of privacy and acceptable handling of information about individuals also shape expectations and preferences of customers, business partners and regulators. Hence, a solid understanding of what privacy is, is crucial for building systems that are not only compliant with the applicable data protection legislation but also cater to customers’ and partners’ privacy needs and preferences.
Much ink has been spilled in attempts to clarify the concept of privacy and a plethora of privacy definitions and conceptualizations has been developed. However, privacy is a very broad concept that often seems to elude clear definition and the almost Babylonian confusion over its meaning and its role make it far from easy “[to articulate] what privacy is and why it is important” (Solove, 2002, p. 1090). Adding to the confusion, different societies have developed different notions of privacy and those notions also change over time.
I will not dive deep into the discussion of the various theories of privacy in this post. Rather, the following will restrict itself to three major “flavors” of privacy conceptualizations to inform the discussion on privacy engineering practice with a solid theoretical foundation. This post will omit any discussions of the differences between privacy and data protection as well as the various variants of the right to privacy. You can find hints to literature on this highly interesting topics at the end of this post.
In this post, I will focus on these three major notions of privacy:
- Privacy as confidentiality
- Privacy as control
- Contextual integrity
Note: I am definitely not the first one to come up with this classification. I build upon, among others, Seda Gürses who provided a very similar overview already in 2014.
Roughly speaking, the “privacy as confidentiality” paradigm focusses on disclosure of private facts and postulates that any unwanted disclosure of personal information, physical or emotional attributes etc. constitutes a loss of privacy. From this perspective, a privacy-preserving system will need to be designed such that it processes as little data on individuals as possible, preferably refraining from any disclosure of personal information at all.
The “privacy as control” paradigm is, in essence, equivalent to the notion of privacy as informational self-determination. Within this framework, privacy is not a black or white situation regarding disclosure of personal data, but a question of whether the individual is able to exercise control over disclosure and usage of their personal data, even after disclosure. From this perspective, a privacy-preserving system will need to offer to individuals far-reaching measures for exercising control over the collection, usage and dissemination of information relating to them. This will also require transparency regarding the processing to enable individuals to actually exercise control.
Finally, the “contextual integrity” paradigm focuses on social norms and the different, dynamic contexts within which flows of personal information are embedded. Within this framework, a privacy violation occurs when personal data is disclosed or used in a way that is at odds with the (negotiated) social norms that apply to this context. From this perspective, a privacy-preserving system will need to be able to consider the context within which it processes personal information. It will also have to be able to apply specific policies matching a given context. Contextual integrity is presented in Helen Nissenbaum’s book “Privacy in Context”, which is well worth reading. However, while it is a highly interesting concept, I will focus on privacy as control and privacy as confidentiality as those have far greater impact on privacy engineering practice.
Both notions (confidentiality and control) are widespread in many societies around the world and highly important factors regarding people’s expectations of privacy-preserving design. With respect to compliance, the notion of privacy as control or informational self-determination is particularly relevant as it is reflected in many data protection laws around the world, most notably in the GDPR. Still, the notion of privacy as confidentiality also resounds strongly in current data protection legislation, for example in the principles of “data minimization” and “integrity and confidentiality” as defined in Art. 5 GDPR.
In addition, the GDPR also strongly reflects the privacy-by-design paradigm hinted at in Part 1 of this series. More accurately, the GDPR enshrines this paradigm into law as the principle of “data protection by design and default” (DPbDD) in its Article 25.
From Theory and Law to Design and Technology
The term “privacy-by-design” was originally used to describe a broad concept aimed at “ensuring privacy and gaining personal control over one’s information and, for organizations, gaining a sustainable competitive advantage” as initially described by Ann Cavoukian, then Privacy Commissioner of Ontario. To achieve these goals, Cavoukian postulated seven principles, e.g., “Privacy embedded into design”, “End-to-end security” or “Full functionality – positive-sum, not zero-sum”.
While the privacy-by-design paradigm is rather old, it has gained renewed importance with the GDPR’s DPbDD obligation. Broadly speaking and citing the ICO “this means [one has] to integrate or ‘bake in’ data protection into [one’s] processing activities and business practices, from the design stage right through the lifecycle”.
As described in Part 1, this baking in of privacy and data protection into systems and SW engineering is at the core of privacy engineering. Aside from organizational & process topics (e.g. Data Protection Impact Assessments or the selection and implementation of organizational measures), this involves, among others, defining privacy-preserving architectures and implementing existing or developing new privacy-preserving technologies (PPTs).
However, as discussed above, common notions of privacy and the resulting data protection regulations only seldom provide requirements that can be translated into technical requirements in a straightforward manner. So-called “protection goals” for privacy engineering can be used to support data protection impact analyses (DPIAs) and the definition of privacy-related requirements. While there are several approaches to conceptualizing privacy engineering protection goals, I will focus on the widely-used protection goals from the “Standard Data Protection Model” (SDM) that can easily be mapped to the principles and obligations laid down in the GDPR.
In addition to the classic CIA triad of confidentiality, integrity and availability commonly used in security engineering, the protection goals for privacy engineering as defined in the SDM further include unlinkability, transparency, intervenability and data minimization:
| Confidentiality | “the requirement that no unauthorised person can access or use personal data” |
| Integrity | “on the one hand […], the requirement that information technology processes and systems continuously comply with the specifications that were defined for them to perform their intended functions […]. On the other hand, […] the property that the data to be processed remain intact […], complete, correct and up-to-date“ |
| Availability | “the requirement that access to personal data and their processing is possible without delay and that the data can be used properly in the intended process.” |
| Unlinkability | “the requirement that personal data shall not be merged, i. e. linked”; closely related to the principle of purpose limitation |
| Transparency | “the requirement that both data subjects […] and system operators […] and competent supervisory bodies […] shall be able to identify to varying degrees which data are collected and processed when and for what purpose in a processing activity, which systems and processes are used to determine where the data are used and for what purpose, and who has legal responsibility for the data and systems in the various phases of data processing” |
| Intervenability | “the requirement that the data subjects’ rights to notification, information, rectification […], erasure […], restriction […], data portability […], objection and obtaining the intervention in automated individual decisions […] are granted without undue delay and effectively if the legal requirements exist […] and data controller is obliged to implement the corresponding measures” |
| Data Minimization | “fundamental requirement under data protection law to limit the processing of personal data to what is appropriate, substantial and necessary for the purpose” |
As depicted below and discussed in more details by Hansen et al., it is not possible to completely fulfill these protection goals simultaneously, as they are pairwise conflicting. Hence, trade-offs are necessary.
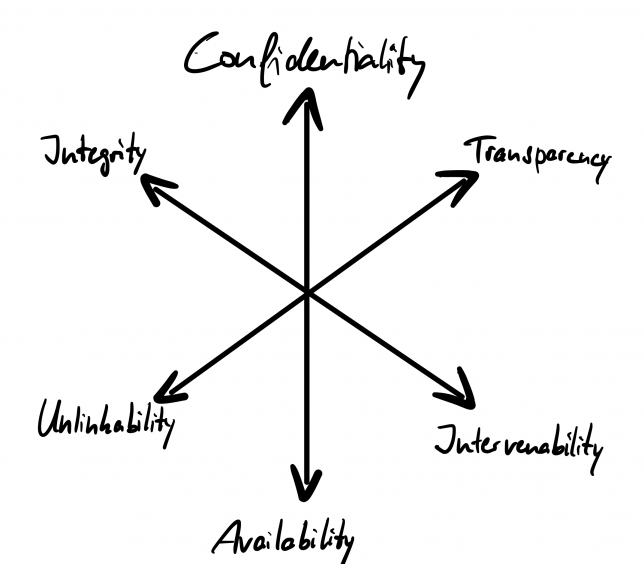
These trade-offs will also determine the selection or development of technical measures (i.e. Privacy-Preserving Technologies (PPTs)) for addressing the protection goals. While data protection legislation and case law define certain obligations and boundaries that have to be considered and complied with, there is ample room for different approaches and focal points when it comes to addressing the protection goals via PPTs. Privacy-Preserving Technologies range from classic security measures such as encryption of data at rest to Transparency-Enhancing Technologies (TETs) such as Dashboards to methods for achieving differential privacy. The selection or development of specific PPTs not only have implications on compliance and trust but can also facilitate new business models, e.g., based on privacy-preserving data pooling.
Part 3 of this series will discuss the different classes of PPTs, illustrate which protection goals they address and which implications on trust and business opportunities they can have.
Additional Reading
- Warren & Brandeis: “The right to Privacy”
- A. Westin: “Privacy and Freedom” (book)
- D. Solove: “A Taxonomy of Privacy”
- S. Gürses: “Can you engineer privacy? On the potentials and challenges of applying privacy research in engineering practice“
- H. Nissenbaum: “Privacy in Context” (book); Paper
- ENISA Report on Data Protection Engineering
- Cranor & Kissner: “Privacy Engineering Superheroes”
- EU Charter of Fundamental Rights Art. 7 Respect for private and family life
- EU Charter of Fundamental Rights Art. 8 Protection of personal data
- J.-H. Hoepman: Privacy is hard and seven other myths (book)
- N. Bhajaria: Data Privacy (book)
- Hansen et al.: Protection Goals for Privacy Engineering
- Business Insider: Consumers are holding off on buying smart-home gadgets thanks to security and privacy fears
- McKinsey: The consumer-data opportunity and the privacy imperative
- “Consumers become more careful about sharing data”
- Accenture: New Global Research from Accenture Interactive Urges CMOs to Put People Before Data Collection to Deliver a Better Digital Advertising Experience
- “More consumers willing to share data when there’s transparency”
- Deloitte: Protecting personal data in the consumer product industry
- “There is a clear connection between consumers’ perceptions of data privacy and security practices and commercial success”
- Accenture: Maximize collaboration through secure data sharing
- “Issues of trust, security and fear of losing competitive advantage prevent organizations from sharing data and collaborating“
- Cisco: Cisco 2021 Data Privacy Benchmark Study
- “Organizations with more mature privacy practices are getting higher business benefits than average and are much better equipped to handle new and evolving privacy regulations around the world”
- Deloitte: The consumer data privacy paradox: Real or not?
- “More than 40% of US consumers don’t trust online services to protect their data”
Christian,
First off, thank you for your series and this post. Continuing the discussion of privacy engineering is important as the profession grows.
I do, however, take issue with two of your core conceptual threads in this post. First, your reliance on compliance and trust suggest only self serving motivations. Both of these suggest the only reason to do privacy is because it will benefit you, the company, through less compliance actions and more business. While true, I disagree with promoting these completely self serving reasons, because it suggest that where the law is absent or the commercial benefits lacking it’s okay to ignore privacy concerns.
We don’t tell children to share with others because they might get something in return eventually. It’s the right thing to do. It’s the moral thing to do. It’s the ethical thing to do. Does this mean you can’t do the right thing and still have the benefit of compliance and trust? No, but the sole focus shouldn’t be this self centered analysis.
Don’t misinterpret me. I really most companies are not so moral or just, so they need to carrot and stick, but we shouldn’t lose focus that privacy is about respecting people.
My second concern with your post is that while you rightly say you don’t want to go into the quagmire of defining privacy, you proceed to define privacy in very three narrow categories. My concern is that, not that these are wrong but rather by restating them here,, you’re reinforcing this mindset. You’re promoting confirmation bias. People who view privacy as confidentiality will find reinforcement in your breakdown. I’m constantly having to disabuse companies and privacy professionals of this notion. Confidentiality is simple to deal with (in relative terms). Most other privacy issues are highly contextual, which makes them difficult.
Just some thoughts to consider.
Thanks for your time
Hi Jason,
first of all, thank you very much for your comment and your time! I really appreciate your feedback and the discussion.
You are, of course, absolutely right regarding that privacy engineering should not only be done for self-serving reasons. Two comments on the whole discussion on trust:
First, there will always be companies that will not care so much about respectful, privacy-preserving data processing. In my opinion, getting them to do at least some privacy, if only for self-serving reasons, is still better than the alternatives. Incentives will probably work better than regulation alone. Still, their is obviously a danger of misincentivation here.
Second, I built my argumentation on some implicit assumptions that I arguably should have elaborated on a bit more. You can surely gain user trust without doing the right thing, at least in the short term. You can easily do so with some “privacy theater” and deceptive practices. For me, however, the whole idea of gaining user trust is necessarily connected to the idea of justified, sustainable trust. That in turn will, so at least my assumption, only build on the basis of (observable) ethically correct, respectful behavior, ie, doing the right thing. Admittedly, this line of argumentation is not so obvious and depending on some hypothesis.
I do agree with you, that the confidentiality perspective is way to narrow. Still, it is out there and I strongly believe that any discussion of the nature of privacy, as superficial as it might be, needs to include the existing perspectives. In particular, as those perspectives resound in current legislation.
Thank you!